패션 프롬프트 엔지니어링: 텍스트 마이닝을 통한 패션 프롬프트 분석 및 구성요소 도출
Abstract
This study conducted text mining on fashion prompts and derived their components to develop a systematic approach to fashion prompt engineering, with the aim of producing results that clearly reflect the designer's intent through human-AI interaction in generating fashion images. As a research method, text mining was performed on 947 fashion prompts shared in a text-to-image AI online database, with the components of the fashion prompts appropriately organized. The results of this study are summarized as follows: First, word frequency and TF-IDF analysis showed that words related to high-fashion photos capturing full-body shots of fashion models or women; highly detailed images on the theme of complex fashion and realistic depictions; image quality; and MidJourney parameters were frequently used in fashion prompts. Second, network visualization of a CONCOR analysis revealed four clusters: 'women's fashion and style,' 'men's fashion and style,' 'photorealistic shooting,' and 'fashion portrait.' It was also found that fashion prompts use words to generate photorealistic images and fashion portrait images containing elements of women's or men's fashion styles as well as elements of shooting. Although there are elements of both women's and men's fashion styles, it was confirmed that the expression of men's styles often involves elements of photorealistic image expression. Third, the components of fashion prompts are broadly categorized into perceptual and technological aspects. The perceptual aspects include subject, model, fashion, background and setting, style, atmosphere, and tone, while the technological aspects include medium, layout, depth and camera, lighting, quality and resolution, and ratio components. This study serves as foundational research for effective fashion prompt engineering, considered as communication between humans and AI. It provides basic data for optimized prompt design towards creative fashion design generation and can be used as educational material for AI-integrated fashion education; moreover, it is expected to contribute to future fashion idea generation and design development.
Keywords:
artificial intelligence, fashion, generate, prompt engineering, text mining키워드:
인공 지능, 패션, 생성, 프롬프트 엔지니어링, 텍스트 마이닝Ⅰ. 서론
AI(artificial intelligence)가 사회, 산업, 예술 및 디자인 등 인간 고유의 창의성을 요하는 분야에 영향을 미치게 되면서 AI 생성에 의한 패션 디자인도 새로운 창의적 접근법으로 주목받고 있다(Guo et al., 2023). 특히, 자연어 설명을 기반으로 이미지를 생성하는 AI는 창의적 패션의 시각적 구현 측면에서 그 효율성과 효과를 명확하게 보여주고 있다. text-to-image AI 생성기는 사용자가 입력하는 프롬프트에 따라 다양한 스타일과 콘텐츠로 이미지를 생성할 수 있고, 시스템을 제어하여 더 많은 변형을 반복할 수 있다(Chung & Lee, 2024). 그러나 특정 스타일의 이미지를 효과적으로 생성하기 위해서는 텍스트 입력 프롬프트를 특정 형식으로 제공하는 것이 요구된다.
텍스트에서 이미지를 생성하려면 text-to-image AI가 원하는 이미지를 생성할 수 있도록 올바른 단어를 선택해야 할 뿐만 아니라 이미지의 스타일과 품질을 제어하기 위해 다양한 키워드와 핵심 문구를 추가해야 한다. 이미지 생성을 위한 텍스트는 자유 형식이고 개방형이기 때문에 텍스트 프롬프트에서 이미지를 생성할 수 있는 가능성은 무궁무진하다. 그러나 이는 이미지를 생성하기 위한 설계 과정에서 쉽게 시행착오가 일어날 수 있음을 의미하기도 한다. 이미지 생성을 시도할 때마다 새로운 텍스트 프롬프트를 찾아야 하는데, 이러한 과정은 무작위하고 원칙이 없는 것처럼 느껴질 수 있다(Liu & Chilton, 2022). 따라서 생성형 AI 시스템을 통해 원하는 결과를 생성하기 위해서는 효과적인 프롬프트를 작성하는 창의적인 프로세스가 요구되며, 이를 '프롬프트 엔지니어링'이라고 한다(Reynolds & McDonell, 2021). 프롬프트 엔지니어링은 AI 생성 모델에 대한 입력 프롬프트를 표현하는 방법일 뿐만 아니라 더 넓은 관점에서 인간이 AI와 효과적으로 상호작용할 수 있는 방법에 대한 것으로, 인간-컴퓨터 상호작용(Human–Computer Interaction: HCI) 분야의 새로운 영역이라고 할 수 있다.
패션 디자인 영역에서 AI를 융합하는 사례들이 증가하면서 패션 디자인에서의 활용 방안(Lee & Lee, 2021; Lee, 2020), HAIC(Human–AI Co-creation) 사례(Chung & Lee, 2023), HAIC를 통한 패션 이미지 생성 시도(Chung & Lee, 2024) 등과 같은 AI 활용 가능성을 고찰한 연구가 활발히 수행되고 있다. 그리고 프롬프트 엔지니어링에 대한 연구(Dehouche & Dehouche, 2023; Kwon, 2024; Liu & Chilton, 2022; Oppenlaender, 2023; Xie, Pan, Ma, Jie, & Mei, 2023; Wang et al., 2022)도 활성화되고 있지만, 패션 이미지 생성 목적하에 활용될 수 있는 패션 프롬프트를 분석한 연구는 수행되지 않았다. 앞에서 언급한 것처럼 프롬프트 엔지니어링은 사용자와 AI의 상호작용을 지원하는 패러다임이자 심층 모델을 조사하는 방법이기 때문에 패션 프로세스에서도 창의적인 패션 이미지 생성을 위해서 프롬프트 엔지니어링에 대한 연구가 수행될 필요가 있다.
이에 본 연구에서는 패션 디자인 생성에 있어서 디자이너의 의도를 명확히 반영하고 더 나은 품질과 창의성을 지닌 결과물을 생성하기 위해서는 어떠한 프롬프트로 AI와 상호작용하고 패션프롬프트 엔지니어링을 체계적으로 수행해야 하는가에 대한 방법을 규명하기 위해 온라인 데이터베이스 플랫폼에서 공유되고 있는 패션 프롬프트를 분석하고, 이를 토대로 구성요소를 도출하고자 한다. 다시 말해서 패션 프롬프트 엔지니어링 최적화 방안을 모색하기 위한 연구로서 본 연구의 결과는 패션 프롬프트 엔지니어링 도구 및 프레임워크 구축 연구에 활용될 수 있을 것이다. 나아가 AI와의 상호작용을 위한 패션 프롬프트에 대한 기본 지식 및 작성 방식을 교육할 수 있는 자료로서 패션 크리에이터 및 전공자들이 AI와의 공동창조를 위한 상호작용의 기본 소양을 갖추는데 기여할 수 있을 것이다. 연구방법은 문헌연구와 실증연구로 진행되는데, 문헌연구에서는 프롬프트 엔지니어링의 개념 및 선행연구를 살펴보고, 프롬프트 구성요소에 대해 고찰한다. 실증연구에서는 text-to-image 온라인 데이터베이스에서 소개된 AI 생성 이미지 중, 패션을 주제로 한 이미지에 대한 입력 프롬프트를 수집해서 텍스트마이닝을 실시하여 패션 프롬프트에 나타난 단어의 빈도, TF-IDF를 추출하고 N-gram, 네트워크를 분석한 다음, 패션 프롬프트 구성요소를 도출하고자 한다.
Ⅱ. 이론적 배경
1. 프롬프트 엔지니어링 관련 선행연구
프롬프트 엔지니어링은 AI 생성 시스템을 위해 텍스트 입력을 작성하는 프로세스로, 프롬프트 디자인(prompt design), 프롬프트 프로그래밍(prompt programming)(Reynolds & McDonell, 2021), 프롬프팅(prompting)이라고도 한다. 프롬프트 엔지니어링은 사용자와 AI와의 대화로, 사용자는 프롬프트를 실행하고 AI가 생성하는 결과를 관찰하며 프롬프트를 조정하여 결과를 개선한다. 이러한 프롬프트 최적화 프로세스는 원하는 콘텐츠, 스타일, 구성 또는 사용자가 생성된 이미지를 통해 전달하고자 하는 기타 특정 속성과 같은 다양한 요소를 구상하고, 프롬프트 입력을 미세하게 조정하여 사용자 의도와 원하는 이미지 간의 불일치를 줄이는 것을 목표로 한다(Liu & Chilton, 2022). 즉, 프롬프트 엔지니어링은 고품질 이미지를 생성하고 사용자 의도를 보다 효과적으로 파악할 수 있게 해준다(Wen et al., 2024).
프롬프트는 사용자 입력 텍스트의 템플릿과 관련된 기술로서 하드 프롬프트와 소프트 프롬프트로 구분된다. 하드 프롬프트의 경우, 고정된 템플릿에 대한 대응만 허용되고 정확한 텍스트 매칭이 요구된다. 예를 들면 AI는 "___와 ___가 있는 ___ 스타일의 그림을 원한다."와 같은 예시를 제공하고 사용자는 빈칸에만 텍스트를 입력할 수 있으며 다른 부분은 수정할 수 없다. 이처럼 하드 프롬프트 모델은 사용자의 정확한 입력을 통해 더 나은 결과를 생성하지만 유연성이 제한적이다. 반면 소프트 프롬프트 기술은 사용자가 미리 정해진 템플릿 없이 자유롭게 텍스트 프롬프트를 입력할 수 있도록 하여 입력 텍스트 템플릿에 응답하는 데 더 큰 유연성을 제공한다. 이러한 유연성은 다양한 작업을 처리할 수 있다는 장점을 지니지만, 입력의 유연성으로 인해 모델이 정확한 정보를 찾는 데 어려움이 있을 수 있다(Wen et al., 2024). 그리고 텍스트 입력 프롬프트에 특정 키워드와 핵심 문구를 추가하면 이미지의 미적 특성과 주관적인 매력은 향상되는데, 이러한 프롬프트 수식어구는 'style phrases', 'clarifying keywords'(Pavlichenko & Ustalov, 2023)로 불리며, 실험, 경험이나 온라인 리소스에서 얻은 모범 사례를 기반으로 적용된다(Oppenlaender, 2023).
선행 연구에서는 text-to-image AI 모델의 생성과 프롬프트 엔지니어링을 조사하기 위해 제한된 키워드 집합에 초점을 맞춘 분석을 실시하였다. Liu & Chilton(2022)은 12가지 주제(love, hate, happiness, sadness, man, woman, tree, river, dog, cat, ocean, forest)와 12가지 스타일(cubist, Islamic geometric art, surrealism, action painting, Ukiyo-e, ancient Egyptian art, high renaissance, impressionism, cyberpunk, unreal engine, Disney, VSCO:2019년 중후반에 청소년들 사이에서 유행하던 미학)로 구성된 프롬프트를 사용하여 프롬프트 순열, 랜덤 시드, 최적화 길이, 스타일 키워드, 주제 및 스타일 키워드에 대한 프롬프트 엔지니어링 실험을 실시했다. 그리고 이를 통해 프롬프트의 순열에 따라서는 생성물의 유의미한 차이가 없기 때문에 프롬프트를 선택할 때 연결어 대신 주제와 스타일 키워드에 집중하는 것이 필요하고 이미지 생성을 통해 유효한 아이디어를 얻기 위해서는 3~9개의 다른 시드 생성하는 것, 다양한 스타일을 시도해 보는 것이 좋다고 제안했다. 또한, 상세한 프롬프트는 더 높은 미적 점수를 지닌 이미지를 생성하고 구체적인 프롬프트가 더 일관된 결과를 제공한다고 하였다.
그리고 온라인 커뮤니티나 데이터베이스, 사용자를 대상으로 프롬프트와 AI 생성 이미지를 분석한 연구들이 수행되었는데, Wang et al.(2022)은 스테이블 디퓨전(Stable Diffusion) 서버에서 수집된 180만 개의 프롬프트를 대상으로 프롬프트의 길이와 언어, 구문 특징을 분석하여 프롬프트의 길이는 짧은 프롬프트(약 6~12개의 토큰)가 가장 많고 대부분 영어로 작성되며, ‘highly detailed’, ‘intricate’, ‘Greg Rutkowski’ 등과 같은 핵심 문구와 페인팅 스타일과 관련된 ‘digital’, ‘oil’, ‘portrait’, 조명과 관련된 ‘studio’, ‘volumetric’, ‘atmospheric’가 프롬프트에 많이 활용되고 있음을 밝혔다. Xie et al.(2023)은 미드저니(Midjourney) 디스코드(Discord) 커뮤니티에서 크롤링한 약 1,448만 8천여 개의 이미지와 프롬프트를 대상으로 프롬프트에서 사용된 단어(토큰)의 빈도와 공출현 빈도, 사용자 입력 패턴, 세션 길이, 사용 빈도 등을 분석하였다. 그리고 이를 통해 프롬프트는 주제, 스타일, 의도를 설명하는 용어로 구성되고, 웹 검색 쿼리와는 달리 더 많은 세부 정보를 포함하고 있으며, 빈번하게 사용된 용어들은 ‘of’, ‘a’, ‘by’ 등이고, 공출현 빈도에서는 ‘detailed painting’ 등과 같이 특정 용어들이 함께 사용되는 패턴이 많이 나타났다고 밝혔다. 그리고 프롬프트의 다양성은 데이터 셋(set)마다 다르게 나타났는데 디퓨전 DB에는 다양한 스타일과 주제를 탐색하는 프롬프트가 많았고, 사용자 행동 분석에서는 일부 사용자는 매우 많은 프롬프트를 입력하여 다양한 이미지를 생성하였지만 대부분의 사용자들은 적은 수의 프롬프트를 입력하는 경향이 있다고 분석하였다.
이 외에도 Liu et al.(2023)은 프롬프트 형태, 답변 엔지니어링 및 작업별 프롬프트를 기반으로 프롬프트를 분류하는 프롬프트 템플릿에 대한 스키마를 연구하였으며, Oppenlaender(2023)는 온라인 text-to-image 커뮤니티의 프롬프트에 대한 분석을 통해 실무자들이 사용하는 6가지 유형의 프롬프트를 분류하였다. Han(2023)은 원하는 이미지를 생성하기 위하여 텍스트 프롬프트와 함께 추가 이미지를 학습하는 인스턴스 프롬프트의 적용과정을 연구하였고 Kwon(2024)은 특정 프롬프트 형식에 대해 AI가 생성해내는 이미지들을 살펴보고 연구자가 입력한 프롬프트를 ChatGPT 4가 이해하고 바꾼 프롬프트를 비교 분석함으로써 연구자가 제안한 프롬프트 구성요소가 유효함을 확인하였다.
위에서 살펴본 바와 같이 특정 주제에 대해 어떤 프롬프트 수식어가 가장 잘 작동하는지 알기 위해서는 사용자의 반복 실험, 온라인 커뮤니티 탐색, 프롬프트 엔지니어링 실행을 지원하기 위한 연구가 필요한 것을 알 수 있다.
2. 프롬프트의 구성요소
AI를 통한 text-to-image 생성을 위한 프롬프트의 구성요소를 구체적으로 살펴본 결과는 <Table 1>과 같다. Oppenlaender(2023)는 text-to-image아트 커뮤니티의 실무자들이 사용하는 수식어를 토대로 6가지 유형의 프롬프트를 주제 용어, 스타일 수식어, 이미지 프롬프트, 품질 부스터, 반복 용어 및 마법 용어로 구분하여 제시했다. 주제 용어는 text-to-image 시스템에서 원하는 주제를 나타낸다. 스타일 수식어는 특정 스타일로 이미지를 생성하기 위해 프롬프트에 포함되며, 이에 따라 AI는 특징적인 스타일 또는 예술적 매체가 반영된 이미지를 생성할 수 있다. 이미지 프롬프트는 text-to-image 시스템에 이미지 합성을 위한 시각적 대상을 제공한다는 점에서 주제 용어 및 스타일 수식어와 유사하게 작동할 수 있고, 일반적으로 텍스트 입력 프롬프트에 추가되거나 별도의 배열로 제공되는 하나 이상의 URL로 지정된다. 품질 부스터는 이미지의 미적 품질과 세부 정보 수준을 높이는 역할을 한다. 반복되는 용어는 생성 시스템에 의해 형성된 연관성을 강화할 수 있다. 예를 들어, ‘a very very very very very beautiful landscape’ 프롬프트는 용어를 반복하지 않는 프롬프트보다 더 나은 이미지를 생성할 가능성이 크다. 이미지에 무작위성을 도입하여 놀라운 결과를 가져올 수 있는 매직 용어(magic terms)는 프롬프트의 주제와 의미적으로 거리가 있을 수 있으며 ‘feed the soul’, ‘feel the sound’와 같이 촉각, 청각, 후각, 미각과 같은 비시각적 특성을 나타낼 수 있다.

Prompt Elements in Text-to-Image Generation through AI
Dehouche & Dehouche(2023)는 스테이블 디퓨전 프롬프트 샘플 분석을 통해 키워드를 범주화했는데, 10가지 기본 요소로서 이미지 속의 캐릭터와 사물을 나타내는 주제, 시각적 개체의 유형이라고 할 수 있는 매체, 이미지를 만드는 데 사용된 도구와 소프트웨어인 기술, 예술적 장르를 설명하는 미적 특징인 장르, 이미지의 분위기와 감정을 설명하는 분위기, 이미지의 색채 구성을 설명하는 특징인 톤, 이미지에서의 빛과 그림자의 사용을 설명하는 조명, 이미지의 세부 사항 수준을 설명하는 해상도, 영감을 얻을 수 있는 아티스트나 예술 작품을 의미하는 예술적 레퍼런스, 예술 중심 플랫폼에서의 수상, 인정 또는 트렌드 상태를 말하는 리셉션/대중성으로 구분하였다. 그 밖에 프롬프트의 2차적 요소로서 주제의 물리적 속성, 주제의 감정적 또는 심리적 특성, 환경/설정, 대칭/반복, 피사계 심도(depth of field), 각도, 메시지/의미를 제시하였다.
한편, Kwon(2024)은 이미지 생성 AI를 직접 사용한 경험과 생성 AI 작가로 활동 중인 킵콴(Keepkwan)의 작업을 토대로 프롬프트 구성요소 1단계로 인식과 기술 측면으로 나눈 다음 2단계, 3단계로 세분화하여 정리하였다. 그는 다양한 프롬프트를 작성하고 적용해 본 결과 프롬프트가 구체적일수록 정확한 이미지를 얻을 수 있었으며 프롬프트를 단계별 개념으로 이해하고 적었을 때 비교적 시행착오를 줄이면서 원하는 결과를 얻을 수 있었다고 설명하였다.
마지막으로 text-to-image의 대표적인 AI 생성기 중에서 고품질 이미지 생성에 적합하고, 예술적 이미지 생성에 강점을 지녀 많은 AI 아티스트들이 사용하고 있는 AI 에이전트 미드저니 플랫폼에는 주제, 매체, 환경, 조명, 컬러, 무드, 구성의 7개 프롬프트 구성요소와 종횡비(ar, aspect, w, h), 에니메이션풍(niji), 의외성(chaos), 이미지 프롬프트 가중치(iw), 예술성(s), 품질(quality, q), 버전(v), 독특성(w), 다양성(c)과 관련된 여러 가지 매개변수 지정 키워드가 제시되어있다.
이상의 프롬프트 구성요소에 대한 선행연구 및 자료를 종합하면 기본적인 요소는 인식적 측면과 기술적 측면으로 구분되고, 인식적 측면은 주제와 인물, 패션, 배경 및 설정, 스타일, 분위기, 톤으로, 기술적 측면은 매체, 레이아웃, 깊이 및 카메라, 조명, 품질 및 해상도, 비율로 분류할 수 있다. 이를 토대로 본 연구에서는 패션 프롬프트에 나타난 단어들을 분석하고 고빈도 키워드들을 위에 나타난 범주에 따라 분류하여 제시하고자 한다.
Ⅲ. 연구 방법
1. 연구문제
본 연구는 text–image AI를 통해 유효한 패션 이미지를 생성하기 위한 패션 프롬프트 엔지니어링에서 요구되는 패션 프롬프트 키워드, 구성요소를 도출하기 위해 다음과 같은 연구문제를 설정하였다.
- 연구문제 1. 패션 프롬프트에 활용되는 고빈도 단어와 TF-IDF를 추출하고 N-gram을 분석하여 전체적인 경향을 확인한다.
- 연구문제 2. 주요 단어들의 네트워크 시각화, CONCOR 분석을 통해 군집화하고 대표 사례를 고찰한다.
- 연구문제 3. 주요 단어들을 토대로 패션 프롬프트 키워드와 구성요소를 도출한다.
2. 자료 수집 및 분석 방법
본 연구는 패션 프롬프트의 키워드 및 구성요소를 도출하기 위해 text–image AI 기반 이미지 생성과 관련된 온라인 데이터베이스 플랫폼을 대상으로 생성된 패션 이미지에 대한 프롬프트를 수집하고 텍스트 마이닝을 실시하였다. 먼저, 포털사이트인 구글(Google) 키워드(fashion prompt, Midjourney prompt for fashion) 검색을 통해 text–to-image AI 기반 이미지 생성 온라인 데이터베이스 플랫폼(arthub.ai; lexica.art; promptden.com; prompthero.com; promptlibrary.org; sprinkleofai.com; www.freemidjourneyprompt.com; www.gate2ai.com, www.promptgaia.com)을 추출하고 해당 플랫폼에서 공유된 이미지 중 패션을 주제로 하는 이미지와 이에 대한 프롬프트를 수집하였다. 효과적인 프롬프트를 작성을 위한 이러한 플랫폼에서 공유되고 있는 프롬프트들은 프롬프트와 생성 이미지 간 일치성이 검증되었다고 볼 수 있다. 패션 이미지들은 모두 미드저니 AI 에이전트로 생성된 것들로 한정하여 수집되었는데, 미드저니는 AI 이미지 생성 도구 중 널리 사용되는 플랫폼으로 이미지 생성이 잘 실현되며 비교적 높은 퀄리티의 결과물을 보여주고 있기 때문이다. 또한, 대부분의 패션 이미지 생성 아티스트들이 이미지 생성시 미드저니를 활용하고 있을 뿐 아니라 이를 통해 생성된 패션 이미지를 기반으로 한 패션위크도 꾸준히 개최되고(Borrelli-Persson, 2023; Kim & Kim, 2023; Park, 2024) 있다.
프롬프트 수집 기간은 2024년 4월 1일부터 6월 30일까지 3개월로, 매주 월요일 해당 온라인 플랫폼들에 접속하여 업데이트되는 내용들을 수집하였다. 수집된 자료는 분석에 필요한 유의미한 단어를 도출하기 위해 형태소 분석, 단어 정규화, 불용어 제거의 데이터 정제를 실시하였다. 먼저, 형태소 분석은 수집된 텍스트가 영어로 되어 있기 때문에 텍스톰(Textom)의 Core NLP를 활용하여 어절들의 품사를 파악한 후, 명사, 형용사, 외국어에 대해 분석하였다. 그리고 각 단어 빈도 전체 보기와 각 단어 간 공출현 빈도를 나타내는 Ngram의 단어를 참고하여 맞춤법에 어긋난 표현, 동일한 의미를 지닌 단어들을 하나로 통합했다. 예를 들어 ‘colour’, ‘colors’는 ‘color’로, ‘grey’는 ‘gray’, ‘photograph’는 ‘photo’, ‘detailed’는 ‘detail’, ‘highly’는 ‘high’로 통합하여 정리하였다. 그리고 불용어는 의존명사와 N-gram과 각 단어별 워드트리를 참고하였는데 맥락을 이해할 수 없거나 뜻을 알 수 없는 단어와 숫자 등은 제거하였다. 처음에 수집된 단어는 4,406건이었고 비정형화된 텍스트를 정제하는 과정을 거쳐 최종 3,867건이 추출되었다.
데이터 분석은 텍스톰을 통해 수집된 단어들의 빈도, 텍스트 내에서 특정한 단어의 중요도를 통계적 수치로 정량화한 TF-IDF, 고빈도 출현 단어들의 동시 출현 빈도와 밀집도를 확인하기 위해 N-gram 분석을 실시하였다. 그리고 도출된 상위 70개 핵심단어와 단어 사이의 일원모드(1-mode) 대칭형 매트릭스를 생성한 후, UCINet 6.798에 있는 NetDraw 기능을 활용하여 단어들 사이의 연결 구조를 시각화하고, CONCOR 분석을 진행하였다.
Ⅳ. 패션 프롬프트 분석 및 구성요소 도출
1. 단어 빈도 및 TF-IDF, N-gram 분석
패션 프롬프트에서 나타난 단어의 빈도와 TF-IDF 분석에서 상위 70개까지를 정리한 결과는 <Table 2>와 같다. 먼저, 빈도에서 가장 많이 나타난 단어는 ‘fashion’, ‘style’이었다. 200회 이상 등장한 단어는 ‘photography’, ‘model’, ‘detail’, ‘color’, v’, ‘dress’, ‘full’, ‘high’, ‘woman’, ‘body’, ‘photo’, black’, ‘q’였다. 그리고 100회 이상 나타난 단어는 white’, ‘realistic’, ‘light’, ‘background’, ‘beautiful’, lighting’, ‘s’, ‘editorial’, ‘cloth’, ‘design’, ‘hyper’ 등이었다. 여기에서 ‘v’는 ‘variation’의 약자로 생성된 이미지 중에서 선택한 이미지를 기준으로 이미지를 다시 생성해 주는 작업, ‘q’는 ‘quality’의 약자로 해상도를 지정하는 작업, ‘s’는 stylize의 약자로 예술성 조절에 활용되는 미드저니 용어이다. 이러한 단어들의 활용은 AI를 통해 여성 모델이 등장하는 특정 스타일의 패션을 착용한 사진과 같은 현실성 있고 디테일이 살아있는 이미지, 드레스, 블랙, 화이트 컬러와 관련된 패션 이미지의 생성 사례가 많은 것으로 해석될 수 있다.
Frequency and TF-IDF Analysis of Top 70 Words on Fashion Prompts
단어의 중요도를 알 수 있는 TF-IDF 분석 결과, 상위 15개 단어는 ‘photography’, ‘detail’, ‘style’, ‘model’, ‘fashion’, ‘color’, ‘dress’, ‘high’, ‘v’, ‘black’, ‘full’, ‘photo’, ‘realistic’, ‘light’, ‘woman’ 순이었다. 그 다음으로는 ‘body’, ‘white’, ‘lighting’, ‘q’, ‘beautiful’, ‘background’, ‘s’, ‘hyper’, ‘design’, ‘cloth’, ‘editorial’, ‘film’, ‘futuristic’, ‘red’, ‘hair’, ‘shot’, ‘outfit’, ‘image’, ‘long’, ‘cinematic’, ‘modern’, ‘ultra’, ‘female’, ‘dark’, ‘focus’, ‘raw’, ‘blue’ 등이 높게 나타났다. 이러한 TF-IDF 분석은 특정 스타일의 패션을 착용한, 사진과 같은 현실성 있는, 디테일이 살아있는 패션 이미지를 생성하기 위한 용어들이 프롬프트 내에서 중요한 역할을 하고 있음을 보여준다. 그리고 패션 이미지에 있어서 블랙과 화이트, 레드 컬러, 아름다움을 강조한, 영화적인, 미래적인 이미지, 현대적인 이미지의 생성 키워드의 텍스트 내 중요도가 높은 것으로 나타났다.
단어의 빈도와 TF-IDF를 비교해보면, 상위 70개 내에 등장하는 단어들은 거의 동일하고 대부분 순위에서만 차이가 있었다. 특히, 상위 6개 단어인 ‘photography’, ‘detail’, ‘style’, ‘model’, ‘fashion’, ‘color’는 순위 차이가 있었지만 빈도와 TF-IDF에서는 동일하게 높은 순위를 차지했다. 특히 ‘detail’과 ‘element’, ‘film’, ‘suit’ 단어들은 빈도 분석보다 TF-IDF 분석에서 상위 순위로 나타나 텍스트 내 중요도가 높은 것을 알 수 있었다.
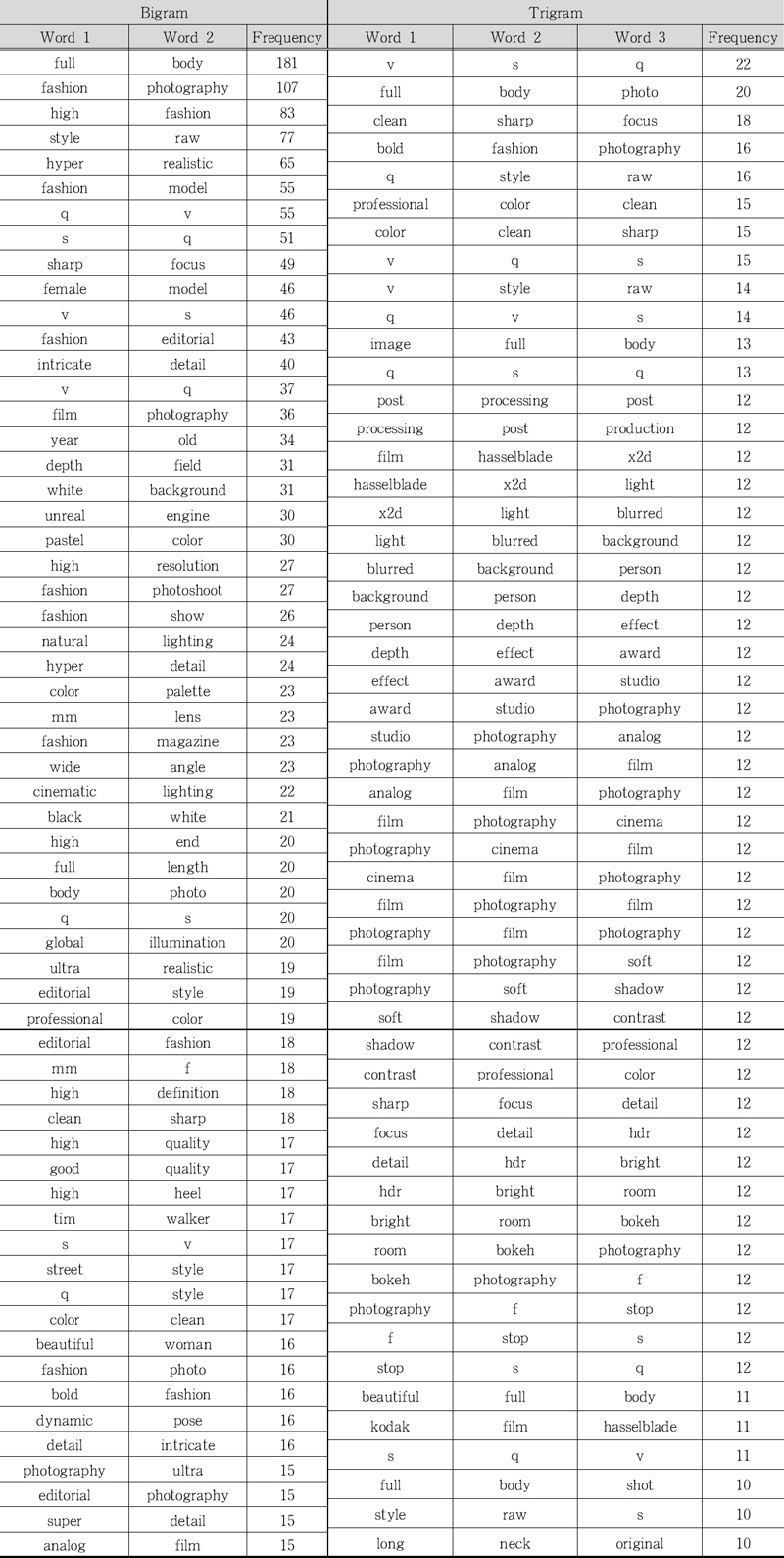
문장 내 연속적인 단어 나열을 의미하는 N-gram 분석에서 바이그램(bigram)은 15회 이상, 트리그램(trigram)은 10회 이상 나타난 결과를 정리하면 <Table 3>과 같다. 그리고 이를 시각화하면 <Fig. 1>, <Fig. 2>와 같다. 먼저 2개의 연속적 단어 나열을 보여주는 바이그램에서는 ‘full body’가 181회로 가장 많았고, ‘fashion photography’가 107회, ‘high fashion’은 83회, ‘style raw’는 77회, ‘hyper realistic’은 65회, ‘fashion model’은 55회, ‘q, v’는 55회, ‘s, q’는 51회 순으로 많이 나타났다. 그 외에는 ‘sharp focus’, ‘female model’, ‘v, s’, ‘fashion editorial’, ‘intricate detail’, ‘v, q’, ‘film photography’, ‘year old’, ‘depth field’, ‘white background’, ‘unreal engine’, ‘pastel color’ 등이 있었다. 3개의 연속적 단어 나열인 트리그램에서는 ‘v, s, q’와 ‘full body photo’가 20회로 가장 많았고, 그 다음으로는 ‘clean sharp focus’, ‘bold fashion photography’, ‘q, style raw’, ‘professional color clean’, ‘color clean sharp’, ‘v, q, s’ 순으로 많이 나타났다. 즉, 빈도 및 TF-IDF에서도 나타났듯이 패션모델 또는 여성의 전신을 담은 패션 사진, 화보 형식의 하이패션, 복잡한 디테일이 살아있는 패션 이미지의 생성을 주제로 한 프롬프트가 서로 연관되어 패션 프롬프트에 많이 나타나고 있음을 알 수 있다. 특히, Wang et al.(2022)와 Xie et al.(2023)의 연구에서 언급된 ‘highly’, ‘detailed’, ‘intricate’ 단어들이 생성 이미지의 세부적 묘사를 위해 활용되는 점이 눈에 띄었다. 이미지 생성의 기술적 측면에서는 프롬프트대로만 생성해 달라고 요청하는 프롬프트인 ‘style raw’, 초현실적인 질감과 사실적인 묘사를 의미하는 ‘hyper realistic’, 이미지 품질과 미드저니 버전, 예술성을 지정하는 매개변수인 ‘q’, ‘v’, ‘s’, 생성 이미지의 포커스와 관련되는 프롬프트인 ‘sharp focus’, ‘depth of field’, ‘clean sharp focus’, 3D 게임 이미지 생성이라는 의미를 담은 ‘unreal engine’과 같은 용어가 많이 활용되었다.
Bigram and Trigram Analysis of the Words on Fashion Prompts

Bigram of the Words on Fashion Prompts

Trigram of the Words on Fashion Prompts
2. 단어 네트워크 시각화와 CONCOR 분석
네트워크 내의 연결 관계 및 패턴을 시각적으로 도출하기 위해 상위 빈도 70개 단어의 동시 출현 상관관계의 일원모드 매트릭스 형성 후, 의미연결망 분석을 실시하였다. CONCOR 분석을 위한 단어의 수는 선행연구(Bae & Lee, 2024; Jang, 2024; Kim & Lee, 2024)들을 참고하여 70개 단어를 사용하였다. 패션 프롬프트에 나타난 단어들의 네트워크 시각화 결과는 <Fig. 3>과 같다. 패션 프롬프트의 단어 네트워크를 보면, ‘fashion’, ‘style’, ‘photography’ 간에 강하게 연결되어 있음을 알 수 있다.

Visualize the top 70 Words Network on Fashion Prompts
중요한 의미를 가지는 고빈도 단어들을 네트워크 상에서 유사한 속성을 가진 군집으로 분류하기 위해 구조적 등위성 분석을 실시했다. 피어슨 상관관계 분석을 토대로 유사한 키워드들로 모인 블록과 그 관계를 파악할 수 있는 CONCOR 분석을 실시한 결과, 4개의 군집이 형성되었다<Fig 4>. 군집 1은 ‘fashion’과 ‘style’을 중심으로 ‘dress’, ‘model’, ‘woman’, ‘high’, ‘white’, ‘black’, ‘v’, ‘q’, ‘cloth’, ‘female’, ‘girl’과 같이 AI 생성 패션 이미지에 있어서 여성 패션과 스타일링, 생성 엔진의 버전과 품질과 관련된 단어들이 포함되어 있어 ‘여성 패션 및 스타일’로 명명하였다. 군집 2는 ‘full’, ‘body’, ‘light’, ‘photo’를 중심으로 ‘background’, ‘hair’, ‘s’, ‘man’, ‘film’, ‘suit’, ‘raw’, ‘long’, ‘dark’ 등과 같은 남성 패션, 배경 및 매체, 주요 주제의 특징과 모습, 예술성 정도를 가리키는 단어들로 ‘남성 패션 및 스타일’로 명명했으며, 군집 3은 ‘photograghy’와 ‘detail’을 중심으로 ‘beautiful’, ‘lighting’, ‘hyper’, ‘mm’, ‘sharp’, ‘photorealistic’, ‘cinematic’, ‘8k’, ‘focus’, ‘ultra’ ‘pose’, ‘soft’ 등의 단어가 포함되어 있어 ‘포토리얼리스틱 촬영’으로 명명했다. 마지막으로 군집 4는 ‘color’를 중심으로 ‘realistic’, ‘design’, ‘portrait’, ‘quality’, ‘modern’, ‘vogue’, ‘outfit’, ‘natural’ 등의 단어들을 포함하고 있어서 ‘패션 포트레이트’로 명명했다. 군집 1과 2는 프롬프트 구성요소에서 인식적 측면에 해당하는 키워드, 군집 3과 4는 기술적 측면에 해당하는 키워드들을 포함하고 있다. 그리고 군집 사이즈는 군집 1이 가장 크고, 군집 2와 3이 유사한 개수의 단어들이 속해 있으며 이들 간의 강력한 연결강도가 나타났다. 반면, 군집 4는 상대적으로 적은 개수, 군집 2, 3과의 연결강도가 약한 것을 알 수 있었다.

CONCOR Analysis of Top 70 Words on Fashion Prompts
이를 통해 패션 프롬프트에는 여성 또는 남성의 패션 스타일 및 촬영 요소를 담은 포토리얼리스틱, 패션 포트레이트 이미지를 생성해낼 수 있는 단어들이 활용되고 있음을 알 수 있다. 그리고 군집의 연결강도 분석 결과는 여성 및 남성 패션 스타일 요소들은 상호 연결성을 가지고 많이 공유되지만 그 표현 방식에 있어서 여성은 포토리얼리스틱 이미지 또는 패션 포트레이트 이미지 구분없이 광범위하게 적용되지만 남성 스타일의 경우에는 포토리얼리스틱 이미지 표현 요소들을 활용하는 경우가 더 많은 것으로 해석될 수 있다.
각 군집의 중심 키워드가 나타난 대표적인 패션 프롬프트(주제 포함 확률이 0.85% 이상) 생성이미지 사례를 정리하면 <Table 4>와 같다. 사례 1의 프롬프트에는 ‘여성 패션 및 스타일’과 ‘포토리얼리스틱 촬영' 군집 키워드를 중심으로 '남성 패션 및 스타일' 군집 키워드 역시 확인할 수 있었다. 특히, ‘sharp fashion photography’는 여성 패션 및 스타일과 포토리얼리스틱 촬영의 밀접한 연관성, ‘detail’은 모델의 모습 또는 표현 매체의 상세한 표현, ‘high’ 키워드는 고해상도 표현을 위해 활용되었음을 알 수 있다. 그리고 ‘style’과 ‘photography’는 이탈리아 패션 사진작가인 파울로 로베르시(Paolo Roversi) 이름과 합쳐져 사진술 스타일을 지정하는 프롬프트로 활용되었다. 이러한 키워드 이외에도 ‘graceful’, ‘elegant’, ‘cyberpunk’, ‘avant-garde’, ‘futuristic’, ‘beautiful’, ‘mysterious’ 등 모델과 착용 복식의 스타일을 나타낼 수 있는 단어와 디지털 카메라를 의미하는 ‘DSLR’, 3D 그래픽적 이미지를 의미하는 ‘open GL’, ‘GLSL’, ‘cel shading’, 사실적인 묘사를 위한 ‘chiaroscuro’, ‘ray tracing’ 등 표현 매체 및 기술과 관련된 단어가 많이 활용되었다. 그리고 사례 1의 프롬프트에는 ‘photography’, ‘photorealistic’, ‘hyperrealistic’ 등의 단어가 반복적으로 활용되었는데, 이러한 용어의 반복은 생성 시스템에 의해 형성된 연관성을 강화하기 위한 것으로(Oppenlaender, 2023) 해석될 수 있다.
Representative Fashion Prompt & Generated Fashion Image
사례 2에서는 ‘여성 패션 및 스타일’ 키워드와 ‘남성 패션 및 스타일’, ‘포토리얼리스틱 촬영’, ‘패션 포트레이트’ 군집의 키워드들이 나타났다. 이외에도 ‘androgynous’, ‘sensual’, ‘goth’, ‘minimalist’ 등의 단어를 비롯해 특정 예술가의 스타일을 나타낼 수 있는 패션 사진작가 ‘Helmut Newton’, 화가 ‘Caravaggio’, 패션 스타일을 의미하는 ‘haute-couture’, 패션 브랜드 ‘Mugler’ 등, 패션 및 레퍼런스 스타일에 대한 구체적인 단어들이 활용되었다. 사례 3도 사례 2와 같이 ‘여성 패션 및 스타일’ 군집의 중심 키워드와 ‘남성 패션 및 스타일’, ‘포토리얼리스틱 촬영’, ‘패션 포트레이트’ 군집 키워드들이 활용되고 구체적인 패션 아이템 및 스타일을 의미하는 ‘haute-couture wears’, ‘sunglasses’, ‘earrings’, ‘nose ring’, 패션 브랜드 ‘Chanel’과 크리에이브 디렉터 ‘Virginie Viard’, 패션 포토그래퍼 듀오 ‘Inez and Vinoodh’ 스타일 등 패션 및 레퍼런스 스타일에 대한 보다 구체적인 단어들이 활용되었다.
사례 4와 5는 남성 모델이 나타나는 패션 이미지에 대한 프롬프트로, 공통적으로 이미지에 나타난 모델의 구체적 연령이 나타났다. 사례 4의 프롬프트에는 ‘남성 패션 및 스타일’의 키워드를 중심으로, ‘포토리얼리스틱 촬영’, ‘여성 패션 및 스타일’ 군집 키워드들이 포함되어 있고 사례 5는 ‘포토리얼리스틱 촬영’, ‘남성 패션 및 스타일’, ‘여성 패션 및 스타일’ 군집 키워드를 중심으로 ‘패션 포트레이트’ 군집 단어들이 포함되어 있다. 이 두사례의 경우, 패션 스타일에 대해서는 각각 ‘dark purple Gucci suit’, ‘high-fashion clothing’으로 비교적 단순한 설명이 있었지만, 배경에 대한 묘사를 포함해 ‘Erwin Olaf’, ‘Mario Testino’의 사진작가 이름, ‘Kodak’, ‘Hasselblade x2D’, ‘Canon EOS’ 카메라, 조명, 렌즈 및 포커스, 해상도, 사진술 등에 대한 상세한 설명이 프롬프트에 포함되었으며, ‘photograghy’ 단어가 반복적으로 강조되어 있음을 알 수 있다. 특히, 사례 5는 프롬프트에 매체, 스타일, 조명, 컬러, 사진 요소에 대한 구성, 비율 등의 항목을 보다 명확히 구분하고 이에 대한 설명을 표시하고 있었다.
마지막으로 사례 6의 프롬프트는 ‘포토리얼리스틱 촬영’과 ‘남성 패션 및 스타일’ 키워드를 중심으로, ‘여성 패션 및 스타일’과 ‘패션 포트레이트’의 단어들을 활용되어 있다. 사례 6은 패션 스타일, 카메라 유형, 렌즈, 조명, 사진술에 대한 설명을 상세하게 포함하고 있다. 그리고 ‘pants, jacket, factories, dreams, pale color palette, zeiss batis, Hasselblad, 35mm f1.2, photorealistic, hyper detailed, 16k, beautiful ambient lighting, dynamic composition, 32k’ 구문을 2회에 걸쳐 반복하고, ‘magical lighting’과 같은 비시각적 마법 용어를 사용해 프롬프트의 주제와 의미를 강조하였다.
3. 패션 프롬프트 구성요소
text-to-image AI를 통해 생성된 패션 이미지 사례들의 프롬프트에 대한 텍스트마이닝분석 결과를 토대로 패션 프롬프트 구성요소를 정리하면 <Table 5>와 같다. 패션 프롬프트의 구성요소는 선행연구를 참고하여 인식적 측면과 기술적 측면으로 대별한 다음 세부 요소에서 인식적 측면은 주제와 모델, 패션, 배경 및 설정, 스타일, 분위기, 톤으로, 기술적 측면은 매체, 레이아웃, 깊이 및 카메라, 조명, 품질 및 해상도, 비율로 분류하였다. 그리고 패션 요소의 경우, 패션 프롬프트 특성상 이에 해당하는 키워드들이 다양하게 포함되어 있어서 이를 각 단어가 나타내는 의미에 따라, 패션 아이템, 형태, 색채, 문양, 소재와 패션 브랜드, 스타일 및 이미지로 분류하여 제시하였다. 각 세부요소에 해당하는 키워드들은 패션 프롬프트에서 10회 이상(상위 330개) 나타난 단어를 예시로 제시하였다. 항목별 단어는 빈도가 높게 나타난 순서대로 제시하였고, ‘high’와 같은 단어는 ‘high fashion’, ‘high resolution’, ‘flower’는 ‘flower detail’, ‘flower print’, ‘flower pattern’, ‘flower background’와 같이 문장 내에서 다양한 방식으로 활용되었기 때문에 각 단어에 대해 연속적인 단어 나열을 의미하는 바이그램 분석 결과를 검토하여 해당되는 항목에 중복해서 기재하였다. 이러한 패션 프롬프트 구성요소에서 인식적 측면은 ‘여성 패션 및 스타일’과 ‘남성 패션 및 스타일’ 군집에 해당하는 키워드들이, 기술적 측면은 ‘포토리얼리스틱 촬영’과 ‘패션 포트레이트’ 군집에 해당하는 키워드들이 포함되어 있다.
Fashion Prompt Components and Examples
인식적 측면의 패션 프롬프트들은 인식가능한 이미지의 주제와 시각적 요소 생성을 제어하는 데 필수적인 기본 요소로 주제, 모델, 패션, 배경 및 설정, 스타일, 분위기, 톤이 포함된다. 이러한 키워드는 AI가 맥락적, 주제적으로 일관된 이미지를 생성하도록 안내하는 지침 역할을 한다. 사용자는 이러한 키워드를 신중하게 선택하고 결합함으로써 AI가 의도한 패션 내러티브와 일치하는 이미지를 생성하도록 제어해야 한다. 주제는 패션 이미지의 주요 객체, 실체 또는 초점으로서 프롬프트에서 핵심 주제, 개념 또는 주요 목적어로 ‘fashion’, ‘style’, ‘aesthetic’, ‘magazine’, ‘high’, ‘design’, ‘collection’, ‘show’, ‘award’ 등이 포함되며, 프롬프트에서는 “__fashion style”과 같이 적용될 수 있다. 모델은 성, 연령, 인체, 표정, 포즈, 국가 등 패션 이미지에 등장하는 모델의 형태적인 특성이나 속성을 가리키는 단어들이 포함되며, ‘body’, ‘hair’, ‘female’, ‘man’, ‘girl’, ‘pose’, ‘young’, ‘face’, ‘old’, ‘front’, ‘big’, ‘skin’, ‘Japanese’, ‘stylish’, ‘African’, ‘mannequin’ 등이 있다. 프롬프트에서는 “__female fashion model”, “__35 years old African man” 등으로 활용된다. 패션은 모델의 복장, 액세서리 또는 스타일 세부 사항, 스타일적 표현에 대한 세부 사항에 해당되는 것으로, 구체적으로 패션 아이템, 형태, 색채, 소재, 문양, 패션 브랜드, 스타일과 이미지 등으로 분류될 수 있다. 패션 아이템 요소에는 ‘cloth’, ‘outfit’, ‘dress’, ‘suit’, ‘jacket’, 형태 요소에는 ‘oversize’, ‘line’, ‘bold’, ‘wide’, ‘silhouette’, 색채 요소에는 ‘color’, ‘black’, ‘white’, ‘bright’, ‘colorful’, 소재 요소에는 ‘flower’, ‘fabric’, ‘texture’, ‘leather’, ‘material’, 패턴 요소에는 ‘flower’, ‘pattern’, ‘line’, ‘print’, ‘logo’, 패션 브랜드 요소에는 ‘Vogue’, ‘Balenciaga’, ‘Gucci’, ‘Nike’, ‘Iris van Herpen’, ‘Dior’, ‘Chanel’, 스타일과 이미지 요소에는 ‘beautiful’, ‘futuristic’, ‘hyper’, ‘dark’, ‘modern’ 등의 단어들이 포함된다. 그리고 이러한 단어들의 조합으로 “__ wearing a dark purple gucci suit”, “__ in a fashionable pastels spotted sweater of textured reality”, “a tailored suit as the foundation of the ensemble, crafted from high-quality fabric such as wool or a fine blend”, “sophisticated color palette” “the suit has a sleek and tailored fit that flatters the body's silhouette.”, “__ for Vogue magazine in the style of James Bidgood” 등과 같이 활용될 수 있다. 배경 및 설정 요소는 패션 이미지의 환경, 시공간적 맥락에 대한 것으로 ‘background’, ‘street’, ‘flower’, ‘scene’, ‘studio’, ‘space’, ‘transparent’, ‘summer’, ‘digital’, ‘1970’, ‘wedding’ 등의 단어들이 포함되며, 프롬프트에서는 “__ in street crosswalk on the road”, “holographic, digital background”와 같이 활용될 수 있다. 스타일 구성요소는 패션이미지 생성에 사용된 시각적 및 예술적 접근 방식으로 아티스트와 장르로 구분되는데, 먼저 아티스트는 ‘Tim Walker’, ‘Wes Anderson’, ‘Nick Night’, ‘Van Gogh’ 등과 같이 사진 작가 또는 영화 감독, 아티스트 이름 등이 활용된다. 장르는 예술 사조와 관련된 ‘surreal’, ‘abstract’, ‘pop’ 등이 포함되고, “__ in the style of Tim Walker”, “__ by Helmut Newton”, “a Wes Anderson color and style”, “surreal fashion photography”, “abstract art of girl wearing __” 등으로 활용된다. 분위기 구성요소는 패션 이미지가 전달하는 감정적 분위기 또는 느낌에 대한 단어로 ‘bright’, ‘dynamic’, ‘elegant’, ‘colorful’, ‘luxury’, ‘sharp’, ‘argument’ 등이 있으며, 톤은 이미지의 색채 구성을 설명하는 특징으로 ‘color’, ‘black’, ‘white’, ‘red’, ‘soft’ 등의 단어들이 포함되며, “elegant futuristic cyberpunk”, “illuminated by a green light”, “mysterious ambiance” 등과 같이 활용될 수 있다.
기술적 측면에 포함된 패션 프롬프트 구성요소들은 시각적 이미지의 매체 유형과 이미지를 만드는데 사용되는 기술, 도구와 소프트웨어 등을 지정하기 위한 단어들을 의미하며 매체, 레이아웃, 깊이 및 카메라, 조명, 품질 및 해상도, 비율 등이 포함된다. 이러한 키워드들을 활용하면 생성 이미지가 시각적으로 보다 매력적이고 높은 품질, 이미지 용도에 따른 요구 사항에 부응할 수 있도록 유도할 수 있다. 먼저 매체는 패션 이미지가 에뮬레이션(emulation)해야 하는 예술적 매체 또는 렌더링 기술 형식을 의미하는 것으로 ‘photography’, ‘v’, ‘c’, ‘photo’, ‘style’, ‘film’, ‘editorial’, ‘raw’, ‘3d’, ‘illustration’, ‘painting’, ‘watercolor’, ‘sketch’ 등 사진, 영화, 그림과 같은 매체 유형뿐 아니라, 수채화, 스케치와 같은 미술 스타일, 고급 렌더링 및 처리 기술, AI 버전과 매개변수 등을 모두 포괄한다. 이와 같은 단어들은 “a sharp fashion photography”, “editorial photo”, “--v 5.1”, “analog film”, “unreal engine”, “style raw”, “pencil draw and watercolor” 등과 같은 형식으로 활용된다. 미드저니에서 활용되는 대표적인 매개변수인 ‘v’, ‘c’, ‘s’는 각각 미드저니 버전, 다양성, 예술성을 의미하는데, 미드저니의 버전은 최신 버전일수록 이미지 퀄리티가 높은 특성이 있으며, 버전마다 더 잘 만드는 특정 스타일이 있다. 그리고 다양성의 기본 설정값은 0이고 최소 0에서 100까지 지정할 수 있으며, 그 값이 클수록 더 다양한 이미지가 생성된다. 예술성의 기본 설정값은 100이고 최소 0에서 1,000까지 지정할 수 있으며, 그 값이 클수록 미드저니의 자체 예술성이 더 많이 반영된다. 레이아웃은 패션 이미지 내의 시각적 요소의 공간적 조직 및 구조를 의미하는 것으로 ‘full’, ‘body’, ‘portrait’, ‘front’, ‘head’, ‘medium’ 등과 같은 단어를 포함하고 프롬프트에서는 “full-length shot”, “head shot”, “_____ portrait”와 같은 형식으로 나타난다. 그리고 깊이와 카메라 구성요소는 ‘shot’, ‘hyper’, ‘f’, ‘focus’, ‘mm’, ‘camera’, ‘lens’, ‘angle’, ‘sharp’, ‘depth’, ‘hdr’, ‘Kodak’, ‘Canon’ 등으로 패션 이미지의 3차원적 측면과 사용된 카메라 종류, 각도, 렌즈 등을 의미하며, “camera with a wide-angle lens”, “Ultra-Wide Angle, Depth of Field”, “Shot with a Canon EOS R5 Mirrorless Digital Camera, RF 503mm” 와 같은 형식으로 패션 프롬프트에 나타난다. 조명은 패션 이미지에서 나타나는 조명과 그림자로, 빛의 품질, 방향 및 강도를 정의할 수 있는 단어인 ‘light’, ‘’dark, ‘cinematic’, ‘soft’, ‘professional’, ‘shadow’, ‘backlight’ 등을 포함하고, 패션 프롬프트에 “a natural backlight”, “softbox lighting”, “soft lighting”, “beautiful ambient lighting” 등과 같이 나타낼 수 있다. 그리고 품질 및 해상도는 패션이미지의 출력의 픽셀 밀도 또는 품질 수준을 지정하는 구성요소로 ‘detail’, ‘q’, ‘high’, ‘realistic’, ‘hyper’, ‘photorealistic’, ‘8k’, ‘resolution’, ‘uhd’ 등과 같은 단어들이 “photorealistic, hyperrealistic, high resolution”, “--q 2”, “super detailed, photography, 8K”와 같이 활용된다. ‘q’ 미드저니 생성에서의 품질 매개변수로 기본 설정값은 1이고 최소 0.25에서2까지 지정할 수 있으며, 그 값이 클수록 품질이 좋지만 생성까지 시간이 오래 걸리는 특징을 지닌다. 마지막으로 비율은 생성되는 패션 이미지의 너비와 높이 사이의 비례 관계인 종횡비를 정의하는데, ‘golden’, ‘ar’ 단어를 활용하여 “golden ratio”, “--ar 4:5”와 같은 형식으로 표시될 수 있다.
Ⅴ. 결론
본 연구는 사용자가 AI와의 상호작용을 통해 의도를 명확히 반영하는 패션 생성물을 생성하기 위해서는 어떻게 패션 프롬프트 엔지니어링을 체계적으로 수행해야 하는가에 대한 방법을 파악하기 위해 온라인 데이터베이스 플랫폼에서 공유되고 있는 패션 프롬프트에 대해 텍스트마이닝을 실시하였으며, 이를 토대로 구성요소를 도출하였다. 본 연구의 결과를 요약하면 다음과 같다.
첫째, 패션 프롬프트에서 나타난 단어의 빈도와 TF-IDF 분석 결과, 상위 6개 단어인 ‘photography’, ‘detail’, ‘style’, ‘model’, ‘fashion’, ‘color’들은 동일하였으나, 순위에만 차이가 있었다. 그 밖에 순위가 높게 나타난 단어들은 ‘v’, ‘dress’, ‘full’, ‘high’, ‘woman’, ‘body’, ‘photo’, ‘black’, ‘q’, ‘realistic’, ‘light’ 등이었다. N-gram 분석에서 바이그램은 ‘full body’, ‘fashion photography’, ‘high fashion’, ‘style raw’, ‘hyper realistic’, ‘fashion model’, ‘q, v’, ‘s, q’, 트리그램은 ‘v, s, q’, ‘full body photo’가 많이 나타난 결과는 빈도 및 TF-IDF에서도 나타났듯이 패션모델 또는 여성의 전신을 담은 하이패션 사진, 복잡한 디테일이 살아있는 패션 이미지의 생성을 주제, 기술적 측면에서는 프롬프트 충실도가 높은 이미지, 초현실적인 질감과 사실적인 묘사, 이미지 품질과 미드저니 버전, 예술성을 지정하는 매개변수와 관련된 단어의 패션 프롬프트에서의 활용이 강조되고 있음을 알 수 있었다.
둘째, 패션 프롬프트에 나타난 단어의 네트워크 시각화와 CONCOR 분석을 실시한 결과, ‘여성 패션 및 스타일’, ‘남성 패션 및 스타일’, ‘포토리얼리스틱 촬영’, ‘패션 포트레이트’의 4개 군집이 도출되었다. 군집 사이즈는 ‘여성 패션 및 스타일’이 가장 크고, ‘남성 패션 및 스타일’과 ‘포토리얼리스틱 촬영’이 유사한 개수의 단어들이 속해 있으며, 이들 간의 강력한 연결강도가 나타난 한편, ‘패션 포트레이트’는 상대적으로 적은 단어의 단어들이 속해 있고 ‘남성 패션 및 스타일’과 ‘포토리얼리스틱 촬영’과의 연결강도가 약한 것으로 나타났다. 이를 통해 패션 프롬프트에는 여성 또는 남성의 패션 스타일 및 촬영 요소를 담은 포토리얼리스틱 이미지 또는 패션 포트레이트 이미지를 생성해낼 수 있는 단어들이 활용되고 있으며, 여성 및 남성 패션 스타일은 각 요소가 서로 공유되지만 표현 방식에 있어서 남성 스타일의 경우에는 포토리얼리스틱 이미지 표현 요소들을 활용하는 경우가 많음을 확인할 수 있었다.
셋째, 패션 프롬프트의 구성요소는 패션 이미지에서 인식가능한 주제, 대상을 제어하기 위한 단어를 의미하는 인식적 측면과 시각적 이미지의 매체 유형과 이미지를 만드는데 사용되는 기술, 도구와 소프트웨어 등을 지정하는 단어들을 의미하는 기술적 측면으로 대별 되었다. 먼저 패션 프롬프트의 인식적 측면은 주제, 모델, 패션, 배경 및 설정, 스타일, 분위기, 톤, 그리고 기술적 측면에는 매체, 레이아웃, 깊이 및 카메라, 조명, 품질 및 해상도, 비율 구성요소가 포함된다. 주제는 패션 프롬프트에서 중심 실체 또는 주요 목적어이고 패션 디테일은 모델의 복장, 액세서리, 스타일적 표현에 대한 세부 사항에 해당되는 것으로, 아이템, 형태, 색채, 소재, 문양, 브랜드, 스타일과 이미지 등으로 분류될 수 있다. 배경 및 설정 요소는 이미지의 환경, 시공간적 맥락, 스타일 구성요소는 시각적 및 예술적 접근 방식으로 아티스트와 장르로 구분되며, 분위기는 감정적 분위기 또는 느낌, 톤은 이미지의 색채 구성을 설명하는 특징을 제어하기 위한 단어들이 포함된다. 그리고 매체는 예술적 매체 또는 렌더링 기술 형식, 레이아웃은 패션 이미지 내의 시각적 요소의 공간적 조직 및 구조, 깊이와 카메라 구성요소는 이미지의 3차원적 측면과 사용된 카메라 종류, 각도, 렌즈 등을 의미하며, 조명은 빛의 방향 및 강도, 그리고 품질 및 해상도는 이미지의 출력 픽셀 밀도 또는 품질 수준, 비율은 패션 이미지의 종횡비를 정의하는 단어들이라고 할 수 있다.
본 연구는 사용자와 text-to-image AI와의 공동 창작과 AI 생성 패션 이미지의 품질을 높이기 위해서 사용자와 AI의 커뮤니케이션이라고 할 수 있는 효율적인 패션 프롬프트 엔지니어링을 위한 기반 연구로서 관련 데이터베이스 플랫폼에서 공유되고 있는 패션 프롬프트에 대한 텍스트마이닝을 시도하였다. 이러한 패션 프롬프트 분석 연구는 패션 이미지 생성에서 AI를 제어하기 위한 프롬프트 구조, 프롬프트 사용 추세와 전략 등을 이해하는 데 기여했다는 점에서 의미가 있다. 그리고 이를 통해 도출된 패션 프롬프트 사례들과 패션 프롬프트 구성요소들은 창의적인 패션 디자인 생성을 위한 최적화된 프롬프트 설계를 위한 연구의 기초자료, AI 융합 패션 교육 자료로 활용될 수 있으며, 향후 창의적인 패션 아이디어 산출 및 디자인 개발에 기여할 수 있을 것으로 사료된다. 이러한 시사점에도 불구하고 본 연구의 결과는 일부 프롬프트 탐색 온라인 데이터베이스, 프롬프트 수집 시기, 미드저니를 통한 생성물에 한한 자료 등 한정된 자료 수집으로 연구 결과를 모든 AI 에이전트 및 사용자에 일반화하기에는 무리가 있을 수 있다. 따라서 후속 연구에서는 본 연구 결과를 통해 도출된 패션 프롬프트 구성요소를 활용해서 각 구성요소 활용 여부 및 순열, 특정 단어의 반복 활용에 따른 생성 패션 이미지에 대한 변화, AI 에이전트 유형, 사용자 특성에 따른 생성물 평가 등을 분석함으로써 패션 프롬프트 엔지니어링의 최적화 방안을 모색해 보고자 한다.
Acknowledgments
이 논문은 2022년 대한민국 교육부와 한국연구재단의 지원을 받아 수행된 연구임 (NRF-2022S1A5B5A16051678).
References
-
Bae, H.-I. & Lee, S.-Y. (2024). Research on sentiment analysis of Hanbok images appearing in big data. Journal of the Korean Society of Costume, 74(3), 54-73.
[https://doi.org/10.7233/jksc.2024.74.3.054]

- Borrelli-Persson, L. (2023, Auguat 29). Exactly what is copy, the first AI-powered fashion magazine, trying to prove?. Vogue. Retrieved from https://www.vogue.com/article/exactly-what-is-copy-the-first-ai-powered-fashion-magazine-trying-to-prove
- Chung, K. & Lee, M. (2023). A case study of human-AI co-creation(HAIC) in fashion design. Journal of Fashion Business, 27(4), 141–162.
-
Chung, K. & Lee, M. (2024). Exploring AI for creative fashion image generation through HAIC. Journal of the Korean Society of Costume, 74(1), 61-87.
[https://doi.org/10.7233/jksc.2024.74.1.061]
-
Dehouche, N. & Dehouche, K. (2023). What’s in a text-to-image prompt? The potential of stable diffusion in visual arts education. Heliyon, 9(6), e16757.
[https://doi.org/10.1016/j.heliyon.2023.e16757]
-
Guo, Z., Zhu, Z., Li, Y., Cao, S., Chen, H., & Wang, G. (2023). AI assisted fashion design: A review. IEEE Access, 11, 88403-88415.
[https://doi.org/10.1109/ACCESS.2023.3306235]
- Han, H. (2023). The study of user customization of AI images training model through instance prompt settings (Unpublished master's thesis). Pusan National University, Republic of Korea.
-
Jang, N. (2024). Sustainable fashion and digital practice through big data text mining-key words analysis of ‘Sustainability+Fashion+Digital’. Journal of Fashion Design, 24(1), 17-32.
[https://doi.org/10.18652/2024.24.1.2]
-
Kim, K. H. & Kim, H. G. (2023). A case study of ChatGPT and Midjourney: Exploring the possiblility of use for art and creation using AI. The Treatise on The Plastic Media, 26(2), 1-10.
[https://doi.org/10.35280/KOTPM.2023.26.2.1]
- Kim, S. & Lee, J. Y. (2024). Analysis of consumers’ perceptions in eco-fashion based on text mining. A Journal of Brand Design Association of Korea, 22(1), 33-44.
-
Kwon, D.-H. (2024). Analysis of prompt elements and use cases in image-generating AI: Focusing on Midjourney, Stable Diffusion, Firefly, DALL·E. Journal of Digital Contents Society, 25(2), 341-354.
[https://doi.org/10.9728/dcs.2024.25.2.341]
- Lee, C.-H. & Lee, J.-H. (2021). The applicability of artificial intelligence based design tools on fashion design thinking. Journal of Korea Design Forum, 26(2), 155-170.
-
Lee, W. Y. (2020). Fashion design education using deep dream generator in intelligence information society. Journal of the Korean Society Design Culture, 26(2), 429-446.
[https://doi.org/10.18208/ksdc.2020.26.2.429]
-
Liu, P., Yuan, W., Fu, J., Jiang, Z., Hayashi, H., & Neubig, G. (2023). Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Computing Surveys, 55(9), 1-35.
[https://doi.org/10.1145/3560815]
-
Liu, V. & Chilton, L. B. (2022). Design guidelines for prompt engineering text-to-image generative models. Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, U.S.A, 1-23.
[https://doi.org/10.1145/3491102.3501825]
- Midjourney (n.d.). Web quick start. Retrieved from https://docs.midjourney.com/docs/web-quick-start
-
Oppenlaender, J. (2023). A taxonomy of prompt modifiers for text-to-image generation. Behaviour & Information Technology, 1-14.
[https://doi.org/10.1080/0144929X.2023.2286532]
- Park, M. (2024, May 7). How the fashion industry is using AI [패션 업계가 AI를 활용하는 방법]. Design. Retrieved from https://design.co.kr/article/14921
-
Pavlichenko, N. & Ustalov, D. (2023). Best prompts for text-to-image models and how to find them. Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, U.S.A., 2067-2071.
[https://doi.org/10.1145/3539618.3592000]
-
Reynolds, L. & McDonell, K. (2021). Prompt programming for large language models: Beyond the few-shot paradigm. Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems, U.S.A., 1-7.
[https://doi.org/10.1145/3411763.3451760]
-
Wang, Z. J., Montoya, E., Munechika, D., Yang, H., Hoover, B., & Chau, D. H. (2022). Diffusiondb: A large-scale prompt gallery dataset for text-to-image generative models. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, 893–911.
[https://doi.org/10.18653/v1/2023.acl-long.51]
- Wen, Y., Jain, N., Kirchenbauer, J., Goldblum, M., Geiping, J., & Goldstein, T. (2024). Hard prompts made easy: Gradient-based discrete optimization for prompt tuning and discovery. Proceedings of the 37th International Conference on Neural Information Processing Systems, U.S.A., 1-15.
-
Xie, Y., Pan, Z., Ma, J., Jie, L., & Mei, Q. (2023). A prompt log analysis of text-to-image generation systems. Proceedings of the ACM Web Conference 2023, U.S.A., 3892-3902.
[https://doi.org/10.1145/3543507.3587430]